
Production ML Papers to Know
Welcome to Production ML Papers to Know, a series from Gantry highlighting papers we think have been important to the evolving practice of production ML.
We have covered a few papers already in our newsletter, Continual Learnings, and on Twitter. Due to the positive reception we decided to turn these into blog posts.
Holistic Evaluation of Language Models
The challenge
Language models (LMs) are becoming ubiquitous in the post-ChatGPT world. But how well do you really understand how the latest models perform? Sure, they have impressive few-shot capabilities and suffer from a tendency to hallucinate. But we’re MLEs, we should be able to quantify that, right?
Typically, researchers assess LMs on a limited subset of their possible applications using a single metric like accuracy. These benchmarks aren’t standardized, making performance comparison hard.
The example of ImageNet showed that AI research benefits from having a generally accepted standard benchmark. Without an equivalent in the LM world, knowledge of the pros and cons of different models is disseminated through word-of-mouth and random twitter threads.
The solution
The main challenge in evaluating LMs is that they are adapted to many different scenarios. This calls for a holistic approach to evaluation.
To that end, the paper proposes HELM (Holistic Evaluation of Language Models), which is based on the following pillars:
- A core set of scenarios that represent common tasks (such as question answering, information retrieval, summarization, toxicity detection) and domains (such as news, books)
- Multi-metric assessment to better represent model impact. Assessing models on calibration, robustness, fairness, bias, toxicity, efficiency - as well as accuracy - in the same scenarios they are expected to be deployed in, can make more explicit the potential tradeoffs for model performance
- Standardization of evaluation, making the object of evaluation the language model and not the scenario-specific system. To this end, the paper benchmarks 30 prominent language models

Results
So what is the impact of standardizing LM evaluation?
The paper reports that, prior to HELM, models were on average evaluated on only 17.9% of the core scenarios - meaning there was no way of comparing results, and no guarantee that the models were assessed against all the scenarios they might be deployed in, nor against the relevant metrics.
HELM evaluated 30 prominent language models to improve this coverage to 96%, facilitating direct, head-to-head comparisons. The chart below illustrates the increase in coverage offered by HELM to previous work in the field.
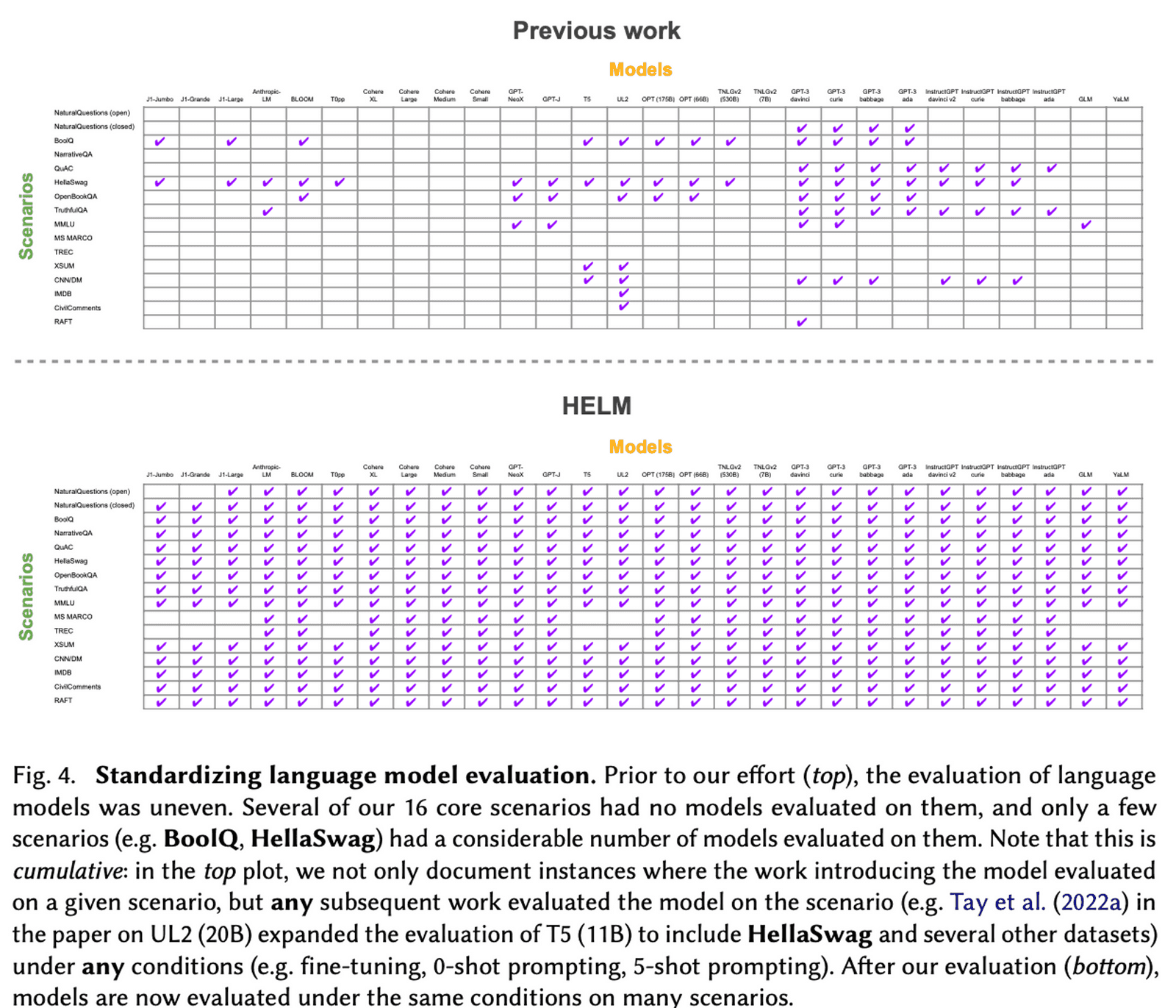
This benchmark used few-shot prompting with relatively simple, generic prompts.
In addition, HELM introduces a taxonomy to understand the evaluation of future LMs. For example, how many of the core scenarios and metrics have been used for a LM’s evaluation? What is missing, and what risks does this incur for future use of that LM?
The chart below, taken from the paper, shows the structure of the taxonomy, broken down into Scenarios and Metrics.

Finally, by evaluating a large number of models, the paper validates some of what we know anecdotally about LM performance.
For example, instruction-tuned models tend to perform better than model types. So do ‘non-open’ models over open access ones. There were consistent performance disparities for different demographics across models, while all models also showed significant sensitivity to prompts, particularly to the formatting of the prompt, and to the choice and number of in-context examples.
The upshot
Hopefully this paper will lead to some much-needed standardization in LM assessment.
The paper is 90 pages long prior to references, and as such contains much more detail than we covered here.
If you are LM developer, or in any way interested in how the technological impact of AI on society can be better evaluated, then we recommend taking a look. You can find the paper here.